引言
本篇文章并不会讲解并行流的使用,因为它的使用很简单,网上的资料也非常的多,正是因为它使用上的简单,才能帮助用户屏蔽大量细节,实现惰性计算,自动并行化等高级功能。本文将剖析流与并行流的执行细节,读完本文后,你看到流代码就能想象出它具体的执行流程。在此之前,笔者已经通读了它的源码与相关文档。
先来看一段简单的流操作:
List<Widget> widgets = new ArrayList<>();
widgets.add(ofWidget(Color.RED, 2));
widgets.add(ofWidget(Color.WHITE, 3));
widgets.add(ofWidget(Color.RED, 5));
widgets.add(ofWidget(Color.RED, 4));
int sum = widgets.stream()
.filter(b -> b.getColor() == Color.RED)
.mapToInt(b -> b.getWeight())
.sum();
下面我将带着大家逐步想象出它的执行流程。
Spliterator
是不是觉得这个单词的拼写有点像 Split + Iterator? 其实它本质上就是一个可以通过 trySplit 方法指导并行流进行数据切分的 迭代器(Iterator)。
就像 Java 的集合类都会通过 iterator() 返回自己的 Iterator 一样,到了Java8,它们也同时定义了一个 spliterator() 方法返回自己的 Spliterator。
有两种方式访问 Spliterator 中数据:
boolean tryAdvance(Consumer<? super T> action):使用action处理该 Spliterator 中下一个元素,并且向下移动一个元素。如果有元素可以处理的话就返回true,否则返回falsevoid forEachRemaining(Consumer<? super T> action):对于 Spliterator 中剩下的所有元素,逐个使用action处理,并移动到 Spliterator 的最后
所有的流都是以一个 Spliterator 作为数据源的,通过 StreamSupport.stream 就可以将一个 Spliterator 转换成一个流,上面的例子中所调用的 Collection.stream 就是这样实现的:
default Stream<E> stream() {
// false 表示是串行流,并行流则传 true
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
Spliterator 和 Iterator 也可以非常方便地互相转换:
- Spliterator 转 Iterator:
Spliterators.iterator(spliterator) - Iterator 转 Spliterator:
Spliterators.spliteratorUnknownSize(iterator)
JDK 有一些 Stream 的实现其实就是用 Iterator 转的,比如 BufferedReader.lines() 返回的流:
public Stream<String> lines() {
Iterator<String> iter = new Iterator<String>() {
String nextLine = null;
@Override
public boolean hasNext() {
if (nextLine != null) {
return true;
} else {
try {
nextLine = readLine();
return (nextLine != null);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
}
@Override
public String next() {
if (nextLine != null || hasNext()) {
String line = nextLine;
nextLine = null;
return line;
} else {
throw new NoSuchElementException();
}
}
};
return StreamSupport.stream(Spliterators.spliteratorUnknownSize(
iter, Spliterator.ORDERED | Spliterator.NONNULL), false);
}
后面我们会学到,并行流是通过切分数据源的方式,正常集合类的 trySplit() 实现都是比较高效的(每次切分一半出去),但是如果 Spliterator 是通过 Iterator 转换过来的话,Iterator 本身又没有切分功能,那它是怎么切分的呢?
因为此时 Spliterator 一组切多大比较合适,就只能非常粗暴地每 1024 个分一组了(事实上这个数字还会不断增大,第二组就是 2048 个,第三组 3072 …..,至于为什么是这个数字,我也不太清楚)。
由此可以看出,如果 Iterator 里面的数据本来就不是非常多的话,转成 Spliterator 后所生成的并行流,可能达不到你想要的效果,甚至和串行流无差。
Pipeline
继续之前的那个例子:
int sum = widgets.stream()
.filter(b -> b.getColor() == Color.RED)
.mapToInt(b -> b.getWeight())
.sum();
为了支持这种链式调用,除了最后的 sum 方法外,其他每个方法返回的都是 Stream 类型的对象,但是 Stream 只是一个接口而已,它具体返回的是什么呢?
答案就是 Pipeline,它们实现了 Stream,你在 sum 之前的一切调用都是在构建一个由 Pipeline 组成的链表链表,而没有进行真正的计算,因此称之为“惰性”。stream() 返回的是一个头接点,而 filter 和 mapToInt 都是在尾部添加节点,并返回尾节点(就是刚添加的那个节点)的引用。
看一下类图你就会更加明白:
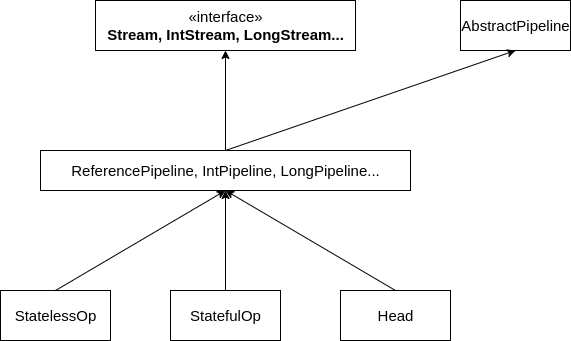
为了让图能够简洁一些,我画的不怎么正式,除了给正常对象使用的 ReferencePipeline(实现了 Stream) ,Java 还为每种基本类型定义了一个 Pipeline,就是图中 IntPipeline(实现了 IntStream), LongePipeline(实现了 LongStream) 以及省略号后面的一堆,在源码中将这些不同的 Pipeline 称为流的“形状”(Shape),为什么要给每种基本类型都定义一种 Pipeline 呢?据说是为了避免频繁的拆箱装箱影响性能。
每种形状的 Pipeline 还分别定义了三个子类,分别是 StatelessOp, StatefulOp 和 Head:
StatelessOp:无状态操作,比如filter,map这种每个元素都可以单独计算StatefulOp:有状态操作,比如sorted,distinct这种需要考虑前后元素的Head:顾名思义,一般作为 Pipeline 的头节点
对照着之前的示例代码:
widgets.stream()返回的就是一个头节点,即ReferencePipeline.Headfilter()是无状态操作,返回的其实就是ReferencePipeline.StatelessOpmapToInt()虽然也是无状态操作,但它的流的形状是基本类型 int,所以返回的是IntPipeline.StatelessOp
假如把 sum 之前构建流的代码单独抽出来:
IntStream myStream = widgets.stream()
.filter(b -> b.getColor() == Color.RED)
.mapToInt(b -> b.getWeight())
最后构建出 myStream 看上去就像下面这样:
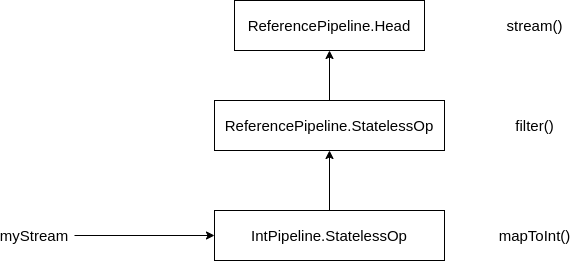
如果你还想进一步确认,可以点开 ReferencePipeline.filter 的源代码看下:
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
// 返回了一个 StatelessOp
// 将 this 作为构造函数的第一个参数,表示以当前的这个 Pipeline 作为上游,链接起来
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
注意它在返回 StatelessOp 的同时还重写了 opWrapSink 方法,记住这个方法,它引出了流中的下一个重要概念-Sink。
Sink
之前的示例代码中,sum 调用之前,我们只是在不断地组装 Pipeline 链表而已,没有做任何实质性地计算。所有的计算都是在 sum 调用中完成。下面我们来深入 它的执行细节。
首先会根据 Pipeline 链表反向构建出一个 Sink 链表(通过 Pipeline 的 opWrapSink 方法):
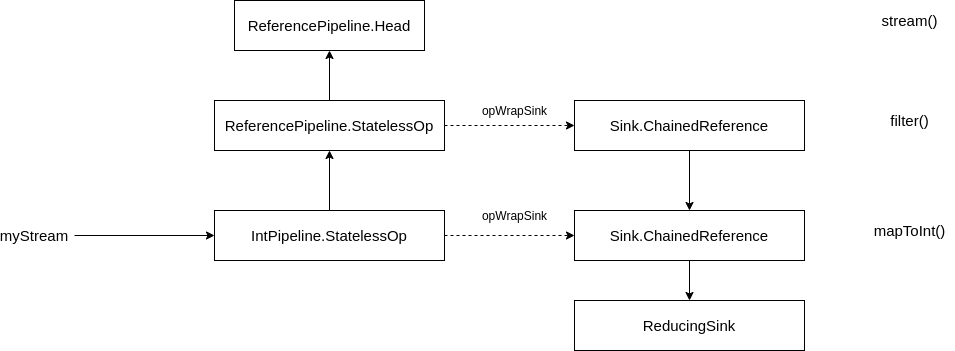
这部分的核心代码位于 AbstractPipeline.wrapSink 中:
// 在之前示例代码中,传入的 sink 就是 ReducingSink
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
看着是不是有点眼熟,这不就是单链表逆序的代码吗?
至于为什么最后是一个 ReducingSink 节点呢?因为 sum 其实调用的是 reduce(如果不理解 reduce 的话,这里简要说一下,其实就是将 (((1+2)+3)+4) 这样的运算应用于 [1,2,3,4],其中 + 可以换成任意自定义运算):
public final int sum() {
return reduce(0, Integer::sum);
}
最后一个 Sink 节点究竟是什么取决于 TerminalOp 是什么,ReduceOp 对应的就是 ReducingSink,其实 TerminalOp 总共就只有四种,而且顾名思义:
ForEachOpReduceOpMatchOpFindOp
最后我们再来明确一下 Sink 接口的具体含义,它最重要的三个方法就是 begin,end 和 accept 方法。
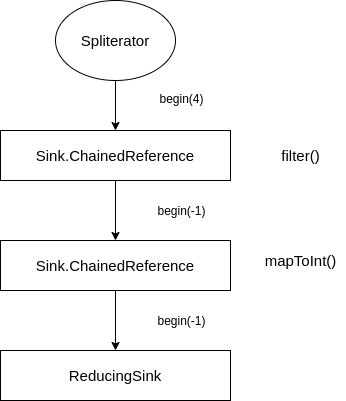
begin(int)用于通知 Sink,表示要开始一批数据传输了,让 Sink 提前做好准备,int 参数表示这一批数据的大小,-1 表示大小未知,这个信息可能对于 filter,map 等操作没有什么用,但是对于 sort 操作则可以提前分配好数组大小。这个 begin 也是会顺着 Sink 链条一路调用下去的,比如经过一个 filter 之后,原本确定的大小就变成了 -1:
begin 调用完成后,Sink 就从初始化状态(initial state)进入激活状态(active state),只有在激活状态下,才可以调用 Sink 的 accept 函数处理数据,正是在这个 accept 函数里,各个操作实现了自己的核心逻辑,比如 filter 操作只有在接收到的数据满足断言时才会传递给下游 Sink 的 accept 方法。
在这一批数据处理完毕后,调用 end 方法,让 Sink 重新从激活状态返回初始化状态,一个简单的示意图如下:

串行流执行
串行流的最终执行位于 AbstractPipeline.copyInto 方法中:
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
wrappedSink 就是之前构建好的 Sink 链,就只需要将 spliterator 作为数据源,源源不断地向 Sink 链中灌数据就可以了,forEachRemaining 方法其实就是在对 spliterator 中的每个元素调用 wrappedSink.accept 方法,这样数据经过层层处理和过滤最终会在 ReducingSink 中沉淀。
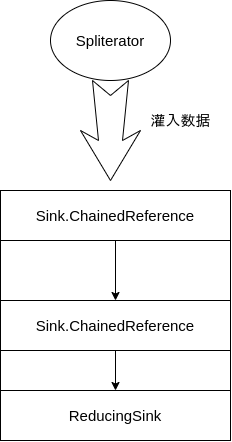
为什么一定要有 begin 和 end 调用呢?看起来直接调用 forEachRemaining 就行了啊。
在串行流中确实看不出有什么用,因为串行流一般就是 forEachRemaining 一路遍历到结束,并不会存在数据分批,这个约定其实是设计给并行流的,串行流的实现只是遵守一下约定而已。
流短路
思考下面一段流代码:
Optional<Integer> find = Arrays.asList(0, 1, 2, 3)
.stream()
.filter(i -> i % 2 == 1)
.findFirst();
System.out.println(find.get()); // 1
上面一段代码找出列表中第一个奇数,逻辑肯定是没有问题的,但是处于程序员的本能,你会思考它的性能是否存在问题,它究竟是会把 0,1,2,3 整个遍历一遍,还是遍历找到 1 后就停止?这对于长列表有很大的性能影响。
流的开发者当然早就想到了这个优化,所以上面这段代码中,流会发生短路,遇到 1 后流就停止了。
还是看 AbstractPipeline.copyInto 方法:
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
//... 正常流计算
}
else {
// 短路流计算
copyIntoWithCancel(wrappedSink, spliterator);
}
}
进入 copyIntoWithCancel:
AbstractPipeline p = AbstractPipeline.this;
// 找到最上层的 Pipeline,也就是 Head
while (p.depth > 0) {
p = p.previousStage;
}
wrappedSink.begin(spliterator.getExactSizeIfKnown());
p.forEachWithCancel(spliterator, wrappedSink);
wrappedSink.end();
其实 copyIntoWithCancel 里面和正常流计算的逻辑差别也不是太大,区别就在于数据来源于 Head 节点的 forEachWithCancel,而不是直接调的 Spliterator 的 forEachRemaining。当然, Head 的数据也还是来自于 Spliterator:
@Override
final void forEachWithCancel(Spliterator<P_OUT> spliterator, Sink<P_OUT> sink) {
do { } while (!sink.cancellationRequested() && spliterator.tryAdvance(sink));
}
和之前直接用 forEachRemaining 直接迭代完全部的数据不同,这里使用 tryAdvance 每次迭代一个元素,就是为了让流支持短路,短路操作对应的 Sink 会在需要短路时让 cancellationRequested() 返回 true,让整个 while 循环退出,剩下的流元素就不迭代了。
findFirst 短路操作对应的 Sink 就是 FindSink:
private static abstract class FindSink<T, O> implements TerminalSink<T, O> {
boolean hasValue;
T value;
FindSink() {} // Avoid creation of special accessor
@Override
public void accept(T value) {
if (!hasValue) {
hasValue = true;
this.value = value;
}
}
@Override
public boolean cancellationRequested() {
return hasValue;
}
//...
}
非常简单,只要 Sink 接收到值就会将 hasValue 置为 true,下一次迭代的时候 cancellationRequested() 方法返回 true 就会将整个流停掉,实现短路。
流中除了 FindOp 这个短路操作外,还提供了下面几个短路操作:
MatchOp:包括anyMath和allMatch操作SliceOp:其实就是limit操作
并行流
铺垫了这么一堆,终于到文章的主题–并行流了。在集合类上调用 parallelStream 或者在串行流上调用 parallel 都可以获得一个并行流,其余的代码没有任何区别。
并行流能够将串行操作并行化,其实也没用什么特别高级的方法,就是最简单的数据并行,之前在将 Spliterator 时也提到过,就是多次调用 trySplit 方法,将数据切成很多份,然后对每一份数据调用串行流的逻辑,每一份都得出一个结果,如果是 forEach 的话,到这里就结束了,对于 reduce 操作,还需要将每一份的结果再合并起来。
注意:因为 “惰性” 的缘故,我上面说的这一切都是在调用流的终结函数时发生,调用中间操作时,还是和串行流一样,构建 Pipeline 链表
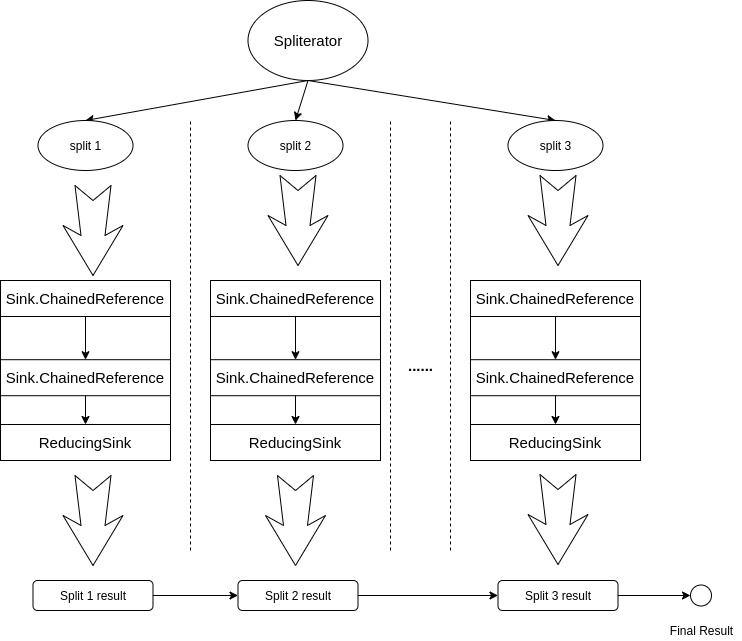
所以 reduce 才有一个叫做 combiner 的参数,它就用来合并每一份结果的逻辑,如果不理解上图,是很难理解这个参数的含义的:
// 统计字符流中 '{' 的数量
int num = Stream.of('{','}','{','}').parallel()
.reduce(0,
// accumulator 负责累计出一份数据的结果
(acc, ch) -> ch == '{'? ++acc: acc,
// combiner 负责将并行的多份结果整合成最终结果
Integer::sum);
需要注意的是,reduce 的 identity 参数应该是一个无状态的“值”,而不应该是一个有状态的对象(比如,不能是一个 ArrayList),因为它会被共享到所有并发的任务中,会出现意想不到的结果。如果你非要想放一个有状态的对象的话,可以考虑 collect,下一小节中我们再详细介绍 collect 的概念与原理。
明眼的小伙伴们一眼就能看出来,刚刚我们说的并行流原理其实只适用于全都是 StatelessOp 的情况,如果流中函数 sorted 这种有状态操作的话,哪能这么完美互不相干地切分数据啊?
我们以下面的流为例:
Stream.of(4, 3, 2, 1).parallel()
.filter(i -> i % 2 == 0)
.sorted()
.map(i -> i * 2)
.reduce(Integer::sum);
其实这种情况的处理也很简单,从 sorted 处,将流切成两半,第一部分将数据收集完后,使用 Arrays.parallelSort 将数据排好后,再作为结果传递给第二部分,第二部分将其作为数据源,计算出最终的结果,一个简单的示意图如下:
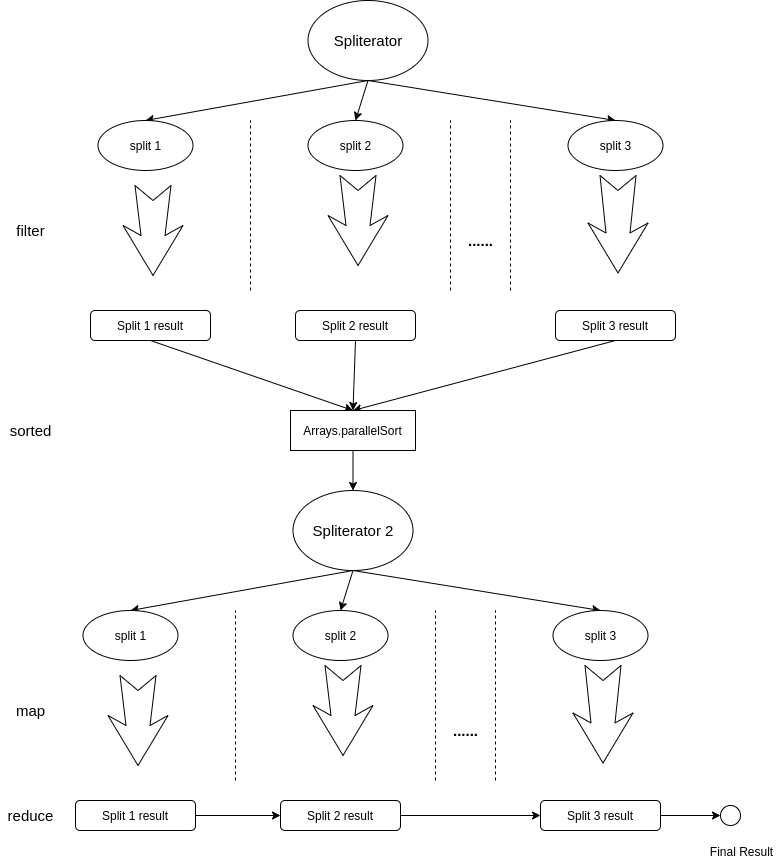
注意:上图的这个流程,依旧都是在流的终结函数(即 reduce)中发生
其他 StatefulOp,比如 distinct,也都是采用这种方式处理的。
collect 和 Collectors
官方文档称 collect 为 “有状态” 的 reduce,collect 方法其实产生的也是一个 reduceOp:
List<Integer> list = Stream.of(1,2,3,4,5).parallel()
.collect(ArrayList::new,
ArrayList::add,
ArrayList::addAll);
这三个参数也和 reduce 的 identity, accumulator 和 combiner 的含义差不多,只不过第一个参数称为 supplier,其实就是“惰性”的 identity,对于每一份数据,调用一次 supplier.get 得到一个单独 identity,于是就避免了之前 reduce 中 identity 多线程共享的问题。
如果每次把流专成 List 都要写上面这么多代码的话,未免太烦人了。所以流的开发者通过 Collectors 类提供了很多现成的 Collector,使用 collect(Collectors.toList()) 和上面的代码效果一样。
Collector 作为一个接口,其中的 supplier,accumulator 和 combiner 方法的含义和三参数 collect 方法中同名参数含义也是类似的。
Collectors 比较有趣的地方是,很多方法提供了一个 downstream 参数,用于将多个 Collector 整合在一起,可以实现一些类似于 SQL 的申明式数据处理。
比如“查询每个部门工资最高的员工”,在 SQL 中我们可以写做:
select department, max(salary) from person group by department;
利用 Collectors 组合功能,我们也能达到类似的效果:
class Person {
String department;
int salary;
public Person(String department, int salary) {
this.department = department;
this.salary = salary;
}
public String getDepartment() {
return department;
}
public int getSalary() {
return salary;
}
}
List<Person> persions = Arrays.asList(new Person("finance", 10000),
new Person("technique", 8999),
new Person("finance", 7888),
new Person("technique", 15662));
Map<String, Optional<Person>> collect = persions.stream()
.collect(
// group by departmant
groupingBy(Person::getDepartment,
reducing(
// max(salary)
BinaryOperator.maxBy(Comparator.comparingInt(Person::getSalary)))
)
);
如何给流拓展其他操作
在使用过程中你会发现 Java 流还是缺少很多方便操作的,比如“压缩”两个流,或者获取流中每个元素的索引等等,在 Guava 的 Streams 工具类中,补充了很多这样的方法:
public class Pair {
int i;
int j;
public Pair(int i, int j) {
this.i = i;
this.j = j;
}
@Override
public String toString() {
return "Pair{" +
"i=" + i +
", j=" + j +
'}';
}
}
// 利用 zip 讲两个整形流压缩成 Pair 流
// Pair(1, 10)
// Pair(2, 20)
Stream<Integer> iStream = Stream.of(1,2);
Stream<Integer> jStream = Stream.of(10, 20);
Streams.zip(iStream, jStream, Pair::new).forEach(System.out::println);
// 给流加上索引
// a:0
// b:1
Streams.mapWithIndex(Stream.of("a", "b"),
(str, index) -> str + ":" + index).forEach(System.out::println);
如果你想自己定义一些流操作可以参考 Streams 里面这些方法的实现,如果你点开他们,会发现也没有什么神奇的。
zip 就是先把两个流的 iterator 取出来,把这两个 iterator 合成一个 Spliterator 后,把 Spliterator 转换成 Stream 后返回:
public static <A, B, R> Stream<R> zip(
Stream<A> streamA, Stream<B> streamB, BiFunction<? super A, ? super B, R> function) {
//... 省略一些校验代码
// 先将两个流的 iterator 取出来
Iterator<A> itrA = Spliterators.iterator(splitrA);
Iterator<B> itrB = Spliterators.iterator(splitrB);
// 组成新 iterator,把新 iterator 转换成
return StreamSupport.stream(
new AbstractSpliterator<R>(
Math.min(splitrA.estimateSize(), splitrB.estimateSize()), characteristics) {
@Override
public boolean tryAdvance(Consumer<? super R> action) {
if (itrA.hasNext() && itrB.hasNext()) {
action.accept(function.apply(itrA.next(), itrB.next()));
return true;
}
return false;
}
},
isParallel)
.onClose(streamA::close)
.onClose(streamB::close);
}
而 mapWithIndex 大概就是先把流的 iterator 取出来后,组合一些逻辑成为 Spliterator,再转换成一个 Stream 返回:
public static <T, R> Stream<R> mapWithIndex(
Stream<T> stream, FunctionWithIndex<? super T, ? extends R> function) {
//...
Spliterator<T> fromSpliterator = stream.spliterator();
Iterator<T> fromIterator = Spliterators.iterator(fromSpliterator);
return StreamSupport.stream(
new AbstractSpliterator<R>(
fromSpliterator.estimateSize(),
fromSpliterator.characteristics() & (Spliterator.ORDERED | Spliterator.SIZED)) {
long index = 0;
@Override
public boolean tryAdvance(Consumer<? super R> action) {
if (fromIterator.hasNext()) {
action.accept(function.apply(fromIterator.next(), index++));
return true;
}
return false;
}
},
isParallel)
.onClose(stream::close);
//...
}

