引言
上一篇文章主要分析了 Sentinel 通知与监控相关的代码。这篇文章我们将分析 Sentinel 最主要的功能-故障切换。
状态转移
整个故障切换的实现,大体上是使用状态机来实现了,存在以下这些状态,sentinel.c:125:
/* 故障转移时的状态 */
// 没在执行故障迁移
#define SENTINEL_FAILOVER_STATE_NONE 0 /* No failover in progress. */
// 正在等待开始故障迁移
#define SENTINEL_FAILOVER_STATE_WAIT_START 1 /* Wait for failover_start_time*/
// 正在挑选作为新主服务器的从服务器
#define SENTINEL_FAILOVER_STATE_SELECT_SLAVE 2 /* Select slave to promote */
// 向被选中的从服务器发送 SLAVEOF no one
#define SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE 3 /* Slave -> Master */
// 等待从服务器转变成主服务器
#define SENTINEL_FAILOVER_STATE_WAIT_PROMOTION 4 /* Wait slave to change role */
// 向已下线主服务器的其他从服务器发送 SLAVEOF 命令
// 让它们复制新的主服务器
#define SENTINEL_FAILOVER_STATE_RECONF_SLAVES 5 /* SLAVEOF newmaster */
// 监视被升级的从服务器
#define SENTINEL_FAILOVER_STATE_UPDATE_CONFIG 6 /* Monitor promoted slave. */
在一次次的 sentinelTimer 定时循环中,状态不断地切换。状态转换过程与条件如下(状态的名称我全部省略了 SENTINEL_FAILOVER_STATE_ 前缀):
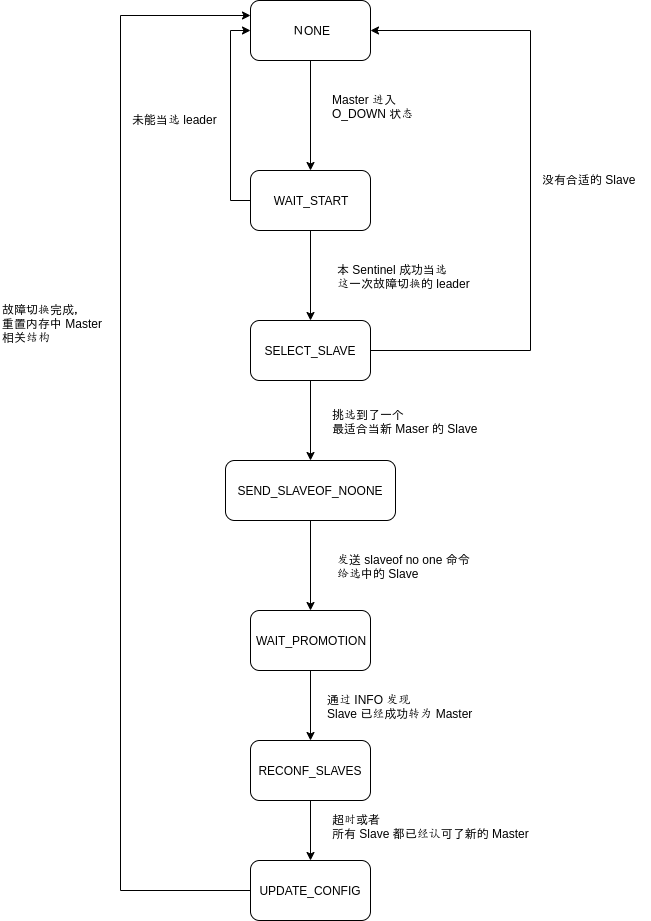
在上一篇文章中我们已经知道,当有大于等于 quorum 数量的 Sentinel 认为 Master 下线时,Master 就进入了 O_DOWN,状态,紧接着就会进入 WAIT_START 的状态,SRI_FAILOVER_IN_PROGRESS 标志位也会被置位,sentinel.c:4200:
// 更新故障转移状态
master->failover_state = SENTINEL_FAILOVER_STATE_WAIT_START;
// 更新主服务器状态
master->flags |= SRI_FAILOVER_IN_PROGRESS;
// 更新纪元
master->failover_epoch = ++sentinel.current_epoch;
需要注意的它同时将当前的 epoch++ 作为 failover_epoch,对 Sentinel 集群来说,每发生一次成功的故障切换,集群中 Sentinel 的 epoch 都会普遍加 1,拥有越高 epoch 的消息一般认为越可信。
状态机最核心的代码位于,sentinel.c:4771:
// 执行故障转移
void sentinelFailoverStateMachine(sentinelRedisInstance *ri) {
//...
switch(ri->failover_state) {
case SENTINEL_FAILOVER_STATE_WAIT_START:
sentinelFailoverWaitStart(ri);
break;
case SENTINEL_FAILOVER_STATE_SELECT_SLAVE:
sentinelFailoverSelectSlave(ri);
break;
case SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE:
sentinelFailoverSendSlaveOfNoOne(ri);
break;
case SENTINEL_FAILOVER_STATE_WAIT_PROMOTION:
sentinelFailoverWaitPromotion(ri);
break;
case SENTINEL_FAILOVER_STATE_RECONF_SLAVES:
sentinelFailoverReconfNextSlave(ri);
break;
}
}
WAIT_START
这个阶段最重要的事情就是选举出负责本次故障切换的 Sentinel(一般称之为 leader)。
Sentinel 会先统计目前已经缓存的其他 Sentinel 的投票情况,选出最大的,sentinel.c:4093:
di = dictGetIterator(counters);
while((de = dictNext(di)) != NULL) {
// 取出票数
uint64_t votes = dictGetUnsignedIntegerVal(de);
// 选出票数最大的人
if (votes > max_votes) {
max_votes = votes;
winner = dictGetKey(de);
}
}
dictReleaseIterator(di);
如果产生 winner 的话,本 Sentinel 也投给它,否则就投给自己,sentinel.c:4113:
if (winner)
// leader_epoch 是 current_epoch 和 epoch 较大的一个
myvote = sentinelVoteLeader(master,epoch,winner,&leader_epoch);
else
myvote = sentinelVoteLeader(master,epoch,server.runid,&leader_epoch);
在 sentinelVoteLeader 函数中也会将 master->leader 设置成它所投票的那个 Sentinel 的 runid,如果之后有别的 Sentinel 使用 SENTINEL is-master-down-by-addr 询问,就会返回这个值给它。
等到最大得票数产生后,还要校验一下,它必须同时大于等于监控该 Master 的 Sentinel 数目的一半和 Master 配置的 quorum,才能最终成为选中的 leader,sentinel.c:4136:
voters_quorum = voters/2+1;
// 最大投票既要大于等于 Sentinel 半数 也要 大于等于quorum
if (winner && (max_votes < voters_quorum || max_votes < master->quorum))
winner = NULL;
如果选出中的 leader 不是自己的话,只要不超时(超时了就只能退回 NONE),就随机退避一段时间再尝试进行故障切换,sentinel.c:4452:
if (!isleader && !(ri->flags & SRI_FORCE_FAILOVER)) {
//...
}
只有自己当选了 leader 才可以进入下一个阶段,sentinel.c:4477:
ri->failover_state = SENTINEL_FAILOVER_STATE_SELECT_SLAVE;
随机退避
如果 Sentinel 竞选 leader 失败,则会随机地退避(2 * failover-timeout - rand(0~1000ms))的时间, 再次尝试竞选。(注:如果不配置 sentinel failover-timeout 的话,failover-timeout 默认是 3 分钟,这里就是6分钟,减去 1s 内的随机时间)。
随机退避的代码藏的比较深,在上面的代码中很难找到,其实在刚刚将状态置为 WAIT_START,就设置了随机的退避时间,sentinel.c:4214:
master->failover_start_time = mstime()+rand()%SENTINEL_MAX_DESYNC;
在每次用 sentinelVoteLeader 函数进行投票时,只要不是投给自己,也都会设置,sentinel.c:4004:
if (strcasecmp(master->leader,server.runid)) // 没有投给自己的情况,退避一段时间
master->failover_start_time = mstime()+rand()%SENTINEL_MAX_DESYNC;
这里的 failover_start_time 其实就是本 Sentinel 下一次尝试故障切换的时间,根据 failover_start_time 进行频率控制的代码则是在 sentinelStartFailoverIfNeeded 函数,sentinel.c:4893:
if (sentinelStartFailoverIfNeeded(ri))
sentinelAskMasterStateToOtherSentinels(ri,SENTINEL_ASK_FORCED);
if (mstime() - master->failover_start_time <
master->failover_timeout*2)
{
//...
}
之所以要引入这种随机性,就是为了避免几个 Sentinel 总是频繁地同时竞选,导致谁也选不上 leader。
拉投票
一旦通过 sentinelStartFailoverIfNeeded 函数发现可以进行一次故障切换,立马就会调用 sentinelAskMasterStateToOtherSentinels 函数像其他 Sentinel 异步拉投票,,其实就是向他们发送 SENTINEL is-master-down-by-addr <master-ip> <master-port> <current-epoch> <runid> 命令,sentinel.c:3954:
retval = redisAsyncCommand(ri->cc,
sentinelReceiveIsMasterDownReply, NULL,
"SENTINEL is-master-down-by-addr %s %s %llu %s",
master->addr->ip, port,
sentinel.current_epoch,
(master->failover_state > SENTINEL_FAILOVER_STATE_NONE) ?
server.runid : "*");
Sentinel 会根据相应结果缓存各个 Sentinel 的投票情况,等到 sentinelTimer 定时函数再一次运行进入状态机时,就像之前讲的一样统计这些缓存的票数,看看自己是否当选。
Sentinel 投票的标准就是 epoch,远端 Sentinel 请求投票发来的 epoch 比如要满足:
- Sentinel 还没有为大于等于该 epoch 的情况投过票
- Sentinel 自己的 current_epoch 小于等于 epoch
否则的话 Sentinel 不会为请求者投票,只会返回自己缓存的投票结果,sentinel.c:3992:
if (master->leader_epoch < req_epoch && sentinel.current_epoch <= req_epoch)
{
//...
SELECT_SLAVE
这个阶段顾名思义,就是挑选一个 Slave 让其切换为新主。
第一波筛选,符合以下条件之一的 Slave 全部刷掉,无资格成为新主:
- 掉线的
- 最后一次 PING 的回复时间距离现在超过 5s
slave_priority被设置为 0 的。其实就是在每个 Slave 的 redis.conf 配置文件中slave-priority 100,这个值设置得越低,越容易在故障切换中被选为 Master,如果是 0 则表示永远都不会选为主- INFO 信息太久没有更新(5s)
- Slave 已经和 Master 失联太久。判断标准是:Master 已经下线的时间 + 5 * down_after_period。这个条件是为了防止选出的 Slave 数据过于陈旧。
相关代码,sentinel.c:4393:
// 忽略所有 SDOWN 、ODOWN 或者已断线的从服务器
if (slave->flags & (SRI_S_DOWN|SRI_O_DOWN|SRI_DISCONNECTED)) continue;
// 最后一次响应 PING 的时间超过 5s
if (mstime() - slave->last_avail_time > SENTINEL_PING_PERIOD*5) continue;
// 被设置不能选为主的 slave
if (slave->slave_priority == 0) continue;
//...
// INFO 回复已过期,不考虑
if (mstime() - slave->info_refresh > info_validity_time) continue;
// 从服务器下线的时间过长,不考虑
if (slave->master_link_down_time > max_master_down_time) continue;
剩下的服务器还要按一定的标准排序,按照优先程度罗列如下:
- 首先考虑
slave_priority,升序 - 复制偏移量,即该 Slave 已经从 Master上同步数据的偏移,降序
- runid,升序
相关代码,sentinel.c:4333:
int compareSlavesForPromotion(const void *a, const void *b) {
//...
}
排第一的就被选为新的 Master了。紧接着它的 SRI_PROMOTED 就会被打开,相应的 RedisInstance 实例也会被放置到 master 的 promoted_slave 字段,最后进行状态转移,sentinel.c:4508:
// 打开实例的升级标记
slave->flags |= SRI_PROMOTED;
// 记录被选中的从服务器
ri->promoted_slave = slave;
// 更新故障转移状态
ri->failover_state = SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE;
SEND_SLAVEOF_NOONE
向刚刚选中的 Slave 发送 SLAVEOF no one 命令,让他成为一个主服务器,紧接着就进入下一个状态了,sentinel.c:4559:
retval = sentinelSendSlaveOf(ri->promoted_slave,NULL,0);
//...
ri->failover_state = SENTINEL_FAILOVER_STATE_WAIT_PROMOTION;
WAIT_PROMOTION
在 sentinelFailoverStateMachine 中与这个状态相关联的函数除了检查超时外什么都没做,那下一个状态的转换在哪里发生的呢?
其实是在该 Slave 的定时 INFO 的回调函数里面,sentinel.c:2607:
// 如果这是被选中升级为新主服务器的从服务器
// 那么更新相关的故障转移属性
if ((ri->master->flags & SRI_FAILOVER_IN_PROGRESS) &&
(ri->master->failover_state ==
SENTINEL_FAILOVER_STATE_WAIT_PROMOTION))
{
// 更新 config_epoch, 会让该 Sentinel 通过 __sentinel__:hello 发布的 Master 信息更加具有权威性
ri->master->config_epoch = ri->master->failover_epoch;
ri->master->failover_state = SENTINEL_FAILOVER_STATE_RECONF_SLAVES;
}
RECONF_SLAVES
到此新的 Master 已经出现了,但是其他 Slave 还不知道新 Master 的存在,这个状态的人物就是让其他 Slave 和新 Master 同步。
其实就是给它们每一个发送一条 SLAVEOF <new-master-ip> <new-master-port>,sentinel.c:4727:
retval = sentinelSendSlaveOf(slave,
master->promoted_slave->addr->ip,
master->promoted_slave->addr->port);
if (retval == REDIS_OK) {
// SRI_RECONF_SENT 标志会被置为
slave->flags |= SRI_RECONF_SENT;
//...
}
它们也是通过 INFO 的回调函数来确认 SLAVEOF 完成的(这里卖弄还有一个从 SRI_RECONF_SENT -> SRI_RECONF_INPROG -> SRI_RECONF_DONE 的过程),sentinel.c:2700:
if ((ri->flags & SRI_SLAVE) && role == SRI_SLAVE &&
(ri->flags & (SRI_RECONF_SENT|SRI_RECONF_INPROG)))
{
/* SRI_RECONF_SENT -> SRI_RECONF_INPROG. */
// 将 SENT 状态改为 INPROG 状态,表示同步正在进行
if ((ri->flags & SRI_RECONF_SENT) &&
ri->slave_master_host &&
// slave_master_host 是从 INFO 返回信息中获得的 master 主机名
strcmp(ri->slave_master_host,
ri->master->promoted_slave->addr->ip) == 0 &&
ri->slave_master_port == ri->master->promoted_slave->addr->port)
{ // Slave 已经开始和新 Master 同步了
ri->flags &= ~SRI_RECONF_SENT;
ri->flags |= SRI_RECONF_INPROG;
sentinelEvent(REDIS_NOTICE,"+slave-reconf-inprog",ri,"%@");
}
/* SRI_RECONF_INPROG -> SRI_RECONF_DONE */
// 将 INPROG 状态改为 DONE 状态,表示同步已完成
if ((ri->flags & SRI_RECONF_INPROG) &&
ri->slave_master_link_status == SENTINEL_MASTER_LINK_STATUS_UP)
{
ri->flags &= ~SRI_RECONF_INPROG;
ri->flags |= SRI_RECONF_DONE;
sentinelEvent(REDIS_NOTICE,"+slave-reconf-done",ri,"%@");
}
}
当所有的 Slave 都已经 SRI_RECONF_DONE(即和新 Master 同步完成),或者故障切换超时,则进入下一个状态,sentinel.c:4631:
if (not_reconfigured == 0) {
//...
master->failover_state = SENTINEL_FAILOVER_STATE_UPDATE_CONFIG;
//...
}
UPDATE_CONFIG
这个状态在 sentinelFailoverStateMachine 中没有对应的处理逻辑,其实在另一个地方被处理了,sentinel.c:4951:
if (ri->failover_state == SENTINEL_FAILOVER_STATE_UPDATE_CONFIG) {
switch_to_promoted = ri;
}
这个状态主要的事情就是重置被故障切换的 RedisInstance 结构体,给它改成新 Master 的地址,将原本的 Master 加入 master->slaves,将升级的 Slave 从中移除等等杂事,sentinel.c:4959:
if (switch_to_promoted)
sentinelFailoverSwitchToPromotedSlave(switch_to_promoted);
常见疑问与解答
如果配置 sentinel.conf 时一不小心将 SENTINEL MONTINOR 配置成了一个从服务器,会怎么样?
答:
- 如果有其他掌握正确 Master 的信息 Sentinel 存在的话,这些 Sentinel 会通过
__sentinel__:hello向它定时发布正确的 Master 信息(即epoch更高的信息),很快该 Sentinel 就会自动切换到正确的 Master 上了 - 如果所有 Sentinel 都配错的话,这个被配错 Slave 很快就会被判角色转换超时(因为我们把它错配成了 Master,而通过定时 INFO 却发现它是 Slave),进入
S_DOWN状态,紧接着就会进入O_DOWN状态,然后进行故障恢复,但是故障恢复会因为找不到合适的 Slave 而失败(因为全部错配成了 Slave,没有办法从 Slave 自动发现其他 Slave),即-failover-abort-no-good-slave
角色转换超时的判断代码,sentinel.c:3746:
if (elapsed > ri->down_after_period ||
// 角色转换超时
(ri->flags & SRI_MASTER &&
ri->role_reported == SRI_SLAVE &&
// role_reported_time 代表 INFO 返回的角色信息, 在每次 INFO 命令返回时更新
mstime() - ri->role_reported_time >
(ri->down_after_period+SENTINEL_INFO_PERIOD*2)))
{
//... 进入 S_DOWN 状态
Sentinel 只在 Master 上订阅 __sentinel__:hello 吗?还是在全部服务器上都有订阅?
答:Sentinel 向其他所有实例(Master, Slave 和 其他 Sentinel)都有订阅 __sentinel__:hello,也会定时向其他所有实例发布自己的消息。
现在可能又会有一个新的疑问,只发布订阅 Master 不就行了吗,为什么其他的也要呢? __sentinel__:hello 的发布订阅主要是为了自动发现 Sentinel 以及帮助集群在 Master 是谁上产生共识,同时发布订阅所有实例有利于网络出现分区时信息更好地流通,使得集群稳定性更好。就比如上一个问题中配错的情况,就因为在 Slave 上的发布订阅而成功纠正了配错的 Sentinel。
Sentinel 是否会处理多层级从服务器,比如从服务器的从服务器?
答:无法处理。源码里只递归了一个层级的 Slave,sentinel.c:4941:
// 只有 Master 会被递归处理 slaves 和 sentinels
if (ri->flags & SRI_MASTER) {
// 所有从服务器
sentinelHandleDictOfRedisInstances(ri->slaves);
// 所有 sentinel
sentinelHandleDictOfRedisInstances(ri->sentinels);
所有 Slave 的 Slave 是不会被监控的,也不可能在故障切换时被选为 Master。
在 RECONF_SLAVES 阶段超时而没能和新 Master 同步的 Slave,之后是怎么同步的?
答:在故障切换完成后, Sentinel 就会更新内存中所有 Slaves (包括 reconf 超时的那些 Slave)指向的 Master 信息,sentinel.c:1768:
for (j = 0; j < numslaves; j++) {
sentinelRedisInstance *slave;
slave = createSentinelRedisInstance(NULL,SRI_SLAVE,slaves[j]->ip,
slaves[j]->port, master->quorum, master);
//...
等到该 Slave 重新连上后,Sentinel 通过定时的 INFO 发现它的信息和内存里认为的对不上,此时就会对该 Slave 发送 slaveof 让他和正确的 Master 同步,sentinel.c:2688:
if ((ri->flags & SRI_SLAVE) &&
role == SRI_SLAVE &&
// 从服务器现在的主服务器地址和 Sentinel 保存的信息不一致
(ri->slave_master_port != ri->master->addr->port ||
strcasecmp(ri->slave_master_host,ri->master->addr->ip)))
{
//...
int retval = sentinelSendSlaveOf(ri,
ri->master->addr->ip,
ri->master->addr->port);
}
什么是脑裂?会有什么样的行为?如何避免?
答:脑裂是指 Redis 集群出现了网络分区,在每个分区分别有一个 Master。不同的 Redis Client 分别在两个分区写数据,互相看不到对方的修改,等到网络分区恢复后,其中一个 Master 的数据会丢失(一般来说是旧的 Master 的数据会丢失,因为它的 epoch 较低)。
如果你无法容忍这种数据丢失的话,可以考虑在 Master 中配置:
min-slaves-to-write N
min-slaves-max-lag M
含义是至少有 N 个 Slave 在 M 秒之内有响应, Master 才能接受写命令。
这个配置本质上是牺牲了可用性,来提升一致性。最坏的情况可能会导致所有的网络分区全部不可写,主要就是看业务是对一致性要求比较高,还是对可用性要求比较高。


