TiDB的初步理解
为什么要有TiDB
个人认为主要目的就是让开发者和运维人员更加省事,体现在以下几点:
- 将OLTP数据库和OLAP数据库一体化了,只需要在部署一套TiDB集群就可以同时实现这两个方面的功能,不需要像以前那样为了OLTP业务部署一套mysql,为了OLAP业务又要再搞一HBase
- 同样因为上面的原因,使用TiDB不需要反复地将数据从OLAP到OLTP数据库中导入和导出,减少了中间流程,降低了发生错误的概率
- 容错性,可拓展性和易用:用户只要负责添加节点即可实现数据库的拓展,使用时和mysql基本一致,只要将其看成一个无穷大容量的mysql即可,并且出错时可以自动恢复。
TiDB的架构
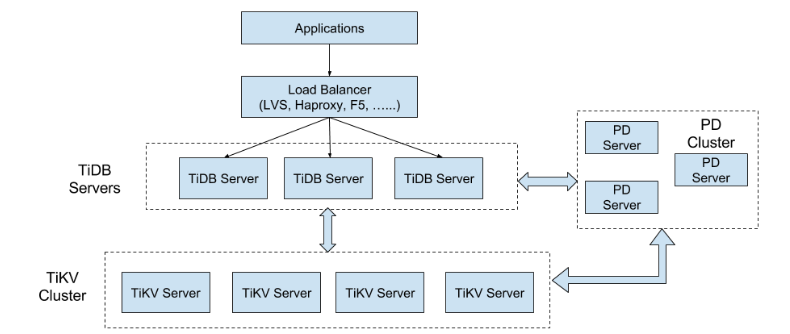
TiDB和传统的OLAP引擎一样,将计算与存储分离,计算层是一个用Go语言实现的SQL引擎,存储层是用Rust实现的一个KV存储TiKV。除此之外还有一个负责调度组件PD(place driver).
TiDB源码走马观花
TiDB Server的启动
配置加载
TiDB的main函数位于tidb-server/main.go
func main() {
flag.Parse()
if *version {
fmt.Println(printer.GetTiDBInfo())
os.Exit(0)
}
registerStores()
registerMetrics()
// 可以加载一个配置文件或者使用默认配置
configWarning := loadConfig()
overrideConfig()
...(略)
}
首先registerStores会注册sql引擎可以使用kv存储,目前只有两个,一个是tikv,还有一个测试用mocktikv:
func registerStores() {
err := kvstore.Register("tikv", tikv.Driver{})
terror.MustNil(err)
tikv.NewGCHandlerFunc = gcworker.NewGCWorker
err = kvstore.Register("mocktikv", mockstore.MockDriver{})
terror.MustNil(err)
}
然后registerMetrics似乎是在prometheus上注册一些评测指标。
之后就是loadConfig就是进行配置加载:
func loadConfig() string {
cfg = config.GetGlobalConfig()
if *configPath != "" {
config.SetConfReloader(*configPath, reloadConfig, hotReloadConfigItems...)
err := cfg.Load(*configPath)
if _, ok := err.(*config.ErrConfigValidationFailed); ok && !*configCheck && !*configStrict {
return err.Error()
}
terror.MustNil(err)
}
return ""
}
代码先去加载默认的配置,然后去configPath读取用户的配置文件。这里的configPath其实就是命令行启动tidb-server时使用的-config参数,如果设置了这个参数的话就会从这个参数读取配置文件,覆盖相关的默认配置。
进入config.GetGlobalConfig()去找找默认配置:
func GetGlobalConfig() *Config {
return globalConf.Load().(*Config)
}
里面globalConf,其实是一个atomic value:
var (
globalConf = atomic.Value{}
...(略)
)
这个atomic value是在config模块的init函数里设值进去的:
func init() {
globalConf.Store(&defaultConf)
...(略)
}
这个defaultConf就是默认的配置,查看这个defaultConf变量可以看到默认配置的内容:
var defaultConf = Config{
Host: "0.0.0.0",
AdvertiseAddress: "",
Port: 4000,
Cors: "",
Store: "mocktikv",
Path: "/tmp/tidb",
...(略)
}
可以看到默认使用的KV存储是测试用的”mocktikv”
main后面一行的overrideConfig()的作用就是用命令行传进来的参数覆盖掉默认配置:
func overrideConfig() {
actualFlags := make(map[string]bool)
flag.Visit(func(f *flag.Flag) {
actualFlags[f.Name] = true
})
// Base
if actualFlags[nmHost] {
cfg.Host = *host
}
if actualFlags[nmAdvertiseAddress] {
cfg.AdvertiseAddress = *advertiseAddress
}
...(略)
}
其中host和advertiseAddress就分别是从命令行参数-host和-advertise-address解析来的值。
从其配置解析的顺序可以看出以下的参数优先级:
命令行参数 > 用户指定的配置文件 > 默认配置
请求处理和协议解析
这一块在server模块中
func main() {
...(略)
runServer()
...(略)
}
func runServer() {
err := svr.Run()
terror.MustNil(err)
}
进入svr的Run方法:
// Run runs the server.
func (s *Server) Run() error {
...(略)
for {
conn, err := s.listener.Accept()
...(略)
// 开启一个协程处理客户端请求
go s.onConn(clientConn)
}
...(略)
}
进入s.OnConn方法:
func (s *Server) onConn(conn *clientConn) {
...(略)
conn.Run(ctx)
...(略)
}
进入conn.Run方法:
func (cc *clientConn) Run(ctx context.Context) {
for {
// 读取一个Packet,MySQL协议规定必须必须采用Packet进行通信
// 一个Packet为16M,不足的用Packet header补齐。
data, err := cc.readPacket()
...(略)
if err = cc.dispatch(ctx, data); err != nil {
...(略)
}
}
}
至此已经将数据以[]byte的形式读进来了,dispatch方法将对该数组进行解析:
func (cc *clientConn) dispatch(ctx context.Context, data []byte) error {
...(略)
// Mysql Packet协议规定,第一个byte表示操作的类型
cmd := data[0]
data = data[1:]
// 对于不同的操作给予不同的处理
switch cmd {
...(略)
//执行sql语句
case mysql.ComQuery: // Most frequently used command.
if len(data) > 0 && data[len(data)-1] == 0 {
data = data[:len(data)-1]
dataStr = string(hack.String(data))
}
return cc.handleQuery(ctx1, dataStr)
...(略)
default:
return mysql.NewErrf(mysql.ErrUnknown, "command %d not supported now", cmd)
}
}
当发现第一个byte是3时,说明是要执行sql的操作,之后会调用handleQuery方法进行sql解析和执行,此时传入handleQuery第二个参数的字符串就已经是sql语句了。
SQL解析
handleQuery的第一行便已经将sql执行完获得结果了,进入cc.ctx.Execute函数。
func (cc *clientConn) handleQuery(ctx context.Context, sql string) (err error) {
rs, err := cc.ctx.Execute(ctx, sql)
...(略)
}
func (tc *TiDBContext) Execute(ctx context.Context, sql string) (rs []ResultSet, err error) {
rsList, err := tc.session.Execute(ctx, sql)
...(略)
}
func (s *session) Execute(ctx context.Context, sql string) (recordSets []sqlexec.RecordSet, err error) {
...(略)
if recordSets, err = s.execute(ctx, sql); err != nil {
s.sessionVars.StmtCtx.AppendError(err)
}
return
}
继续进入s.execute方法:
func (s *session) execute(ctx context.Context, sql string) (recordSets []sqlexec.RecordSet, err error) {
...(略)
// Step1: Compile query string to abstract syntax trees(ASTs).
startTS := time.Now()
// 每一条sql语句都被翻译成了一个StmtNode结构的抽象语法树
stmtNodes, warns, err := s.ParseSQL(ctx, sql, charsetInfo, collation)
...(略)
for idx, stmtNode := range stmtNodes {
s.PrepareTxnCtx(ctx)
// Step2: Transform abstract syntax tree to a physical plan(stored in executor.ExecStmt).
...(略)
// 对这个语句进行验证和优化
// 对sql做执行规划, 成为一个ExecStmt结构, ExecStmt里面有个Plan字段为执行计划
stmt, err := compiler.Compile(ctx, stmtNode)
...(略)
// Step3: Execute the physical plan.
//执行这个sql语句
if recordSets, err = s.executeStatement(ctx, connID, stmtNode, stmt, recordSets); err != nil {
return nil, err
}
}
...(略)
}
这一部分比较复杂,暂时先理解成产出StmtNode和ExecStme结构交给执行阶段,就不细看了。
从s.executeStatement方法开始进入SQL的执行阶段
SQL执行
func (s *session) executeStatement(ctx context.Context, connID uint64, stmtNode ast.StmtNode, stmt sqlexec.Statement, recordSets []sqlexec.RecordSet) ([]sqlexec.RecordSet, error) {
...(略)
// 执行
recordSet, err := runStmt(ctx, s, stmt)
...(略)
}
func runStmt(ctx context.Context, sctx sessionctx.Context, s sqlexec.Statement) (rs sqlexec.RecordSet, err error) {
...(略)
rs, err = s.Exec(ctx)
...(略)
}
func (a *ExecStmt) Exec(ctx context.Context) (sqlexec.RecordSet, error) {
...(略)
// 将plan转换成executor
e, err := a.buildExecutor(sctx)
if err != nil {
return nil, err
}
...(略)
// 立即执行 no delay
if e.Schema().Len() == 0 {
return a.handleNoDelayExecutor(ctx, sctx, e)
} else if proj, ok := e.(*ProjectionExec); ok && proj.calculateNoDelay {
return a.handleNoDelayExecutor(ctx, sctx, e)
}
...(略)
//只有Query返回recordSet,此时延迟执行(应该是调用Next时)
return &recordSet{
executor: e,
stmt: a,
txnStartTS: txnStartTS,
}, nil
}
下面拆分一下上面的代码,首先是执行计划转成Executor:
func (a *ExecStmt) buildExecutor(ctx sessionctx.Context) (Executor, error) {
...(略)
// 根据不同的语句构建出不同的Executor
e := b.build(a.Plan)
...(略)
}
func (b *executorBuilder) build(p plannercore.Plan) Executor {
switch v := p.(type) {
...(略)
case *plannercore.Insert:
return b.buildInsert(v)
...(略)
}
}
这里就只看看insert语句的执行器的构建:
func (b *executorBuilder) buildInsert(v *plannercore.Insert) Executor {
...(略)
insert := &InsertExec{
InsertValues: ivs,
OnDuplicate: append(v.OnDuplicate, v.GenCols.OnDuplicates...),
}
return insert
}
可以看出最后返回了一个InsertExec结构体,这个结构体实现了Executor接口。
executor包中有很多xxxExec名称的结构体,通过阅读其Next方法的实现大概就能知道它是被怎么在KV存储上执行的。
有两个地方可能会调用Next方法:
- 在ExecStmt.Exec方法中的
a.handleNoDelayExecutor调用(对于无返回值的INSERT, UPDATE等SQL)
func (a *ExecStmt) handleNoDelayExecutor(ctx context.Context, sctx sessionctx.Context, e Executor) (sqlexec.RecordSet, error) {
...(略)
err = e.Next(ctx, chunk.NewRecordBatch(e.newFirstChunk()))
if err != nil {
return nil, err
}
...(略)
}
- 在tidb-server给服务器写回数据的时候,之前提到的clientConn.handleQuery方法中调用的writeResultset和writeMultiResultset方法(对于有返回值的SQL)
顺带阅读一些InsertExec的Next方法,理解一下TiDB与KV存储之间的交互:
func (e *InsertExec) Next(ctx context.Context, req *chunk.RecordBatch) error {
...(略)
// 只看比较简单的 insert ... values (...)...的情况
// 传入了自己的exec方法
return e.insertRows(ctx, e.exec)
}
func (e *InsertValues) insertRows(ctx context.Context, exec func(ctx context.Context, rows [][]types.Datum) error) (err error) {
...(略)
return exec(ctx, rows)
}
省略掉的那一坨代码大概就是将表达式求值得到要插入数据库的具体的值rows,然后调用exec方法插入数据库。exec之前传入的就是InsertExec的exec方法,然后查看这个方法:
func (e *InsertExec) exec(ctx context.Context, rows [][]types.Datum) error {
...(略)
} else {
// 逐行插入记录
for _, row := range rows {
if _, err := e.addRecord(row); err != nil {
return err
}
}
}
return nil
}
就只看最简单的逐行插入记录吧。继续追踪e.addRecord方法:
func (e *InsertValues) addRecord(row []types.Datum) (int64, error) {
...(略)
h, err := e.Table.AddRecord(e.ctx, row)
...(略)
}
继续追踪e.Table.AddRecord,似乎有好多实现,就看tableCommon的吧
func (t *tableCommon) AddRecord(ctx sessionctx.Context, r []types.Datum, opts ...*table.AddRecordOpt) (recordID int64, err error) {
if !hasRecordID {
// 分配记录id, 看起来是直接就用本地原子变量 + 1
// 多个tidb-server的情况下是怎么处理冲突的还不太清楚???
recordID, err = t.AllocAutoID(ctx)
if err != nil {
return 0, err
}
}
...(略)
// Insert new entries into indices.
// 构造索引
h, err := t.addIndices(ctx, recordID, r, rm, &opt.CreateIdxOpt)
if err != nil {
return h, err
}
...(略)
key := t.RecordKey(recordID)
writeBufs.RowValBuf, err = tablecodec.EncodeRow(ctx.GetSessionVars().StmtCtx, row, colIDs, writeBufs.RowValBuf, writeBufs.AddRowValues)
if err != nil {
return 0, err
}
value := writeBufs.RowValBuf
// 写入行数据
if err = txn.Set(key, value); err != nil {
return 0, err
}
...(略)
}
细化一下构建索引的过程:
func (t *tableCommon) addIndices(ctx sessionctx.Context, recordID int64, r []types.Datum, rm kv.RetrieverMutator,
opt *table.CreateIdxOpt) (int64, error) {
...(略)
// 逐个更新index
for _, v := range t.WritableIndices() {
...(略)
// 构造索引
if dupHandle, err := v.Create(ctx, rm, indexVals, recordID, opt); err != nil {
if kv.ErrKeyExists.Equal(err) {
return dupHandle, dupKeyErr
}
return 0, err
}
...(略)
}
...(略)
}
在v.Create方法中才真正将索引插入数据库:
func (c *index) Create(ctx sessionctx.Context, rm kv.RetrieverMutator, indexedValues []types.Datum, h int64,
opts ...*table.CreateIdxOpt) (int64, error) {
...(略)
// 生成Index的存储Key
key, distinct, err := c.GenIndexKey(ctx.GetSessionVars().StmtCtx, indexedValues, h, writeBufs.IndexKeyBuf)
if err != nil {
return 0, err
}
...(略)
if !distinct {
// non-unique index doesn't need store value, write a '0' to reduce space
// 对于非Unique的索引, value直接给0
err = rm.Set(key, []byte{'0'})
return 0, err
}
var value []byte
if !skipCheck {
// 检验该key是否重复
value, err = rm.Get(key)
}
if skipCheck || kv.IsErrNotFound(err) {
// key没有重复的话则直接Set, h就是recordID
err = rm.Set(key, EncodeHandle(h))
return 0, err
}
...(略)
}
至于Key的编码过程上面的代码再往里面点一层就能看到了,因为说计算已经讲地很清楚了,我就没有细看。有机会再细看


